Hai hai hai, Sahabat Esgulian..
Masih semangatkan, buat mencari informasi dalam rangka mencerdaskan diri?
Kali ini Kita mau belajar tentang bagaimana sih caranya memperoleh mean, median dan modus dari suatu data ststistika baik tunggal maupun berkelompok?
Nah jadi sahabat semua, Rataan (Mean), Median dan Modus didalam ilmu statistika merupakan bagian dari ukuran pemusatan data. Ukuran pemusatan data adalah sembarang ukuran yang menunjukkan pusat segugus data, yang telah diurutkan dari yang terkecil sampai yang terbesar atau sebaliknya dari yang terbesar sampai yang terkecil.
Udah gak sabar kan? Yuks Pantengin!
Nah, kita memiliki suatu data berkelompok yang tersaji seperti gambar berikut :

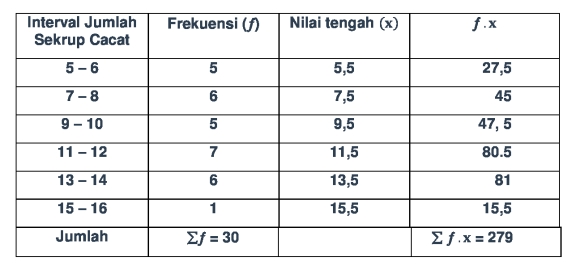
Dapat kita ketahui dari data statistik diatas menjelaskan tentang jumlah sekrup baja yang cacat pada setiap produksi. Data tersebut berfungsi untuk mengevaluasi kegiatan produksi, sehingga untuk produksi kedepannya dapat meminimalisasi produk yang gagal. Melalui data tersebut, dapat dilihat bahwa cara pengumpulan datanya melalui survey dengan metode stratified random sampling. Dimana sampel yang digunakan dapat mewakili dari produk setiap dilakukan produksi.
Selanjutnya data yang telah didapat disajikan menjadi diagram batang seperti pada gambar tersebut. Tampilannya yang mudah dipahami dan cukup representatif apabila digunakan untuk evaluasi kinerja. Namun apabila kita ingin menelisik lebih jauh dan menginginkan tampilan yang lebih kompleks, dapat kita coba dengan menggunakan tabel distribusi frekuensi.
| Interval Jumlah Sekrup Cacat | Frekuensi (f) | |
| 5 – 6 | 5 | |
| 7 – 8 | 6 | |
| 9 – 10 | 5 | |
| 11 – 12 | 7 | |
| 13 – 14 | 6 | |
| 15 – 16 | 1 | |
| Jumlah | 30 | |
Nah, dari data berkelompok tersebut kita akan mencari mean, median, dan modusnya. Tapi, sebelumnya, Kita review tentang apasih mean, median, dan modus itu? Dan apa perbedaan dari mean, median, dan modus dari data tunggal dan data berkelompok? Oke langsung cus aja yuk!
a. Mean
Mean atau rata-rata hitung adalah nilai yang diperoleh dari jumlah sekelompok data dibagi dengan banyaknya data. Rata-rata disimbolkan dengan x.
- Rata-Rata untuk Data Tunggal
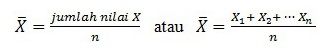
Keterangan:
ẋ = mean
n= banyaknya data
ẋ = mean
n= banyaknya data
Contoh Rataan Data tunggal
Hitunglah nilai rata-rata dari nilai ujian matematika kelas 3 SMU berikut ini: 2, 4, 5, 6, 6, 7, 7, 7, 8, 9.
Jawab:

- Rata-Rata untuk Data Berkelompok

Keterangan :
fi = frekuensi
xi = nilai tengah
Nilai tengah adalah jumlah tepi bawah dan tepi atas di bagi 2.
fi = frekuensi
xi = nilai tengah
Nilai tengah adalah jumlah tepi bawah dan tepi atas di bagi 2.
Oke langsung kita coba, menggunakan data berkelompok yang telah kita punya :

b. Median
Median adalah nilai data yang terletak di tengah setelah data diurutkan. Dengan demikian, median membagi data menjadi dua bagian yang sama besar. Median (nilai tengah) disimbolkan dengan Me.
- Median untuk Data Tunggal
- Jika banyaknya data n ganjil
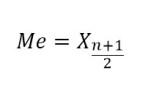
- Jika banyaknya data n genap
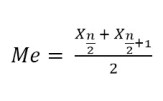
Keterangan:
Me = Median
n = jumlah data
x = nilai data
Contoh Median Data Tunggal
Tentukan median dari data berikut.
- 8,6,4,3,7,5,8,10,8,9,8,5
- Sepuluh orang siswa dijadikan sampel dan dihitung tinggi badannya. Hasil pengukuran tinggi badan kesepuluh siswa tersebut adalah sebagai berikut.172, 167, 180, 171, 169, 160, 175, 173, 170, 165Hitunglah median dari data tinggi badan siswa!
Jawab :
- Data diurutkan : 3 4 5 5 6 7 8 8 8 8 9 10
N= 12 (genap)
Jadi, mediannya adlah 7,5 - Karena jumlah data genap, maka penghitungan median menggunakan rumus median untuk data genap. Proses penghitungannya adalah sebagai berikut.
 Untuk melanjutkan penghitungan, kita harus terlebih dahulu mengetahui nilai x5 dan x6. Kedua nilai data tersebut dapat diperoleh dengan mengurutkan semua data. Hasil pengurutan adalah sebagai berikut.160, 165, 167, 169, 170, 171, 172, 173, 175, 180Dari pengurutan tersebut diperoleh nilai x5 sama dengan 170 dan x6 sama dengan 171. Dengan demikian penghitungan median dapat dilanjutkan.
Untuk melanjutkan penghitungan, kita harus terlebih dahulu mengetahui nilai x5 dan x6. Kedua nilai data tersebut dapat diperoleh dengan mengurutkan semua data. Hasil pengurutan adalah sebagai berikut.160, 165, 167, 169, 170, 171, 172, 173, 175, 180Dari pengurutan tersebut diperoleh nilai x5 sama dengan 170 dan x6 sama dengan 171. Dengan demikian penghitungan median dapat dilanjutkan.


- Median untuk data berkelompok

Keterangan :
Tb = Tepi bawah kelas median (Batas bawah – 0,5)
F = Frekuensi kumulatif sebelum median
f = Frekuensi
c = Panjang kelas
n = Jumlah frekuensi
Tb = Tepi bawah kelas median (Batas bawah – 0,5)
F = Frekuensi kumulatif sebelum median
f = Frekuensi
c = Panjang kelas
n = Jumlah frekuensi
Yuk kita coba lagi, menggunakan data berkelompok yang telah kita punya :

- Letak kelas median: Setengah dari seluruh data = 30, terletak pada kelas ke-3 (jumlah 9-10)
- Tb = 9 – 0,5 = 8,5
- c = 2
- n = 80, f = 24
- f = 5 (frekuensi kelas median)
- F = 5 + 6 = 11

c. Modus
Modus adalah data yang paling sering muncul atau memiliki frekuensi tertinggi. Modus dilambangkan dengan Mo. Beberapa kemungkinan tentang modus suatu gugus data:
- Apabila pada sekumpulan data terdapat dua modus, maka gugus data tersebut dikatakan bimodal.
- Apabila pada sekumpulan data terdapat lebih dari dua modus, maka gugus data tersebut dikatakan multimodal.
- Apabila pada sekumpulan data tidak terdapat modus, maka gugus data tersebut dikatakan tidak mempunyai modus.
- Modus untuk data tunggal
Modus dari data tunggal adalah data yang paling sering muncul.
Contoh :
Tentukan modus dari data berikut !
4, 8, 7, 4, 6, 3, 6, 8, 6, 3
Jawab :
Data yang paling sering muncul adalah 6, maka Mo = 6
- Modus untuk data berkelompok

Keterangan :
Tb = Tepi bawah kelas modus
d1 = Selisih antara frekuensi modus dengan frekuensi sebelumnya
d2 = selisih antara frekuensi modus dengan frekuensi sesudahnya
c = Panjang kelas
Nah, berapa nilai modus dari data berkelompok yang kita punya?

- Kelas modul = kelas ke-4
- Tb = 11-0.5 = 10.5
- b1 = 7 – 5 = 2
- b2 = 7 – 6 = 1
- c = 2

SKEWENESS (KECONDONGAN)
Kecondongan suatu kurva dapat dilihat dari perbedaan letak mean, median dan modusnya. Jika ketiga ukuran pemusatan data tersebut berada pada titik yang sama, maka dikatakan simetris atau data berdistribusi normal. Sedangkan jika tidak berarti data tidak simetris atau tidak berdistribusi normal.
Ukuran kecondongan data terbagi atas tiga bagian, yaitu :
- Kecondongan data ke arah kiri (condong negatif) dimana nilai modus lebih dari nilai mean (modus > mean).
- Kecondongan data simetris (distribusi normal) dimana nilai mean dan modus adalah sama (mean = modus).
- Kecondongan data ke arah kanan (condong positif) dimana nilai mean lebih dari nilai modus (mean > modus).


Dari gambar grafik diatas dapat kita lihat bahwa nilai modus lebih dari pada nilai mean (modus>mean). Sehingga Skewness (kecondongan) dari data tersebut adalah Skewed to the left or negatively skewed (Kecondongan data ke arah kiri atau condong negatif).
Comments
Post a Comment